
Research process at a glance
- 01Literature Review
- 02Dataset Curation
- 03Labeling Protocol
- 04LLM Pipeline
- 05Comparative Evaluation
- 06Design Implications
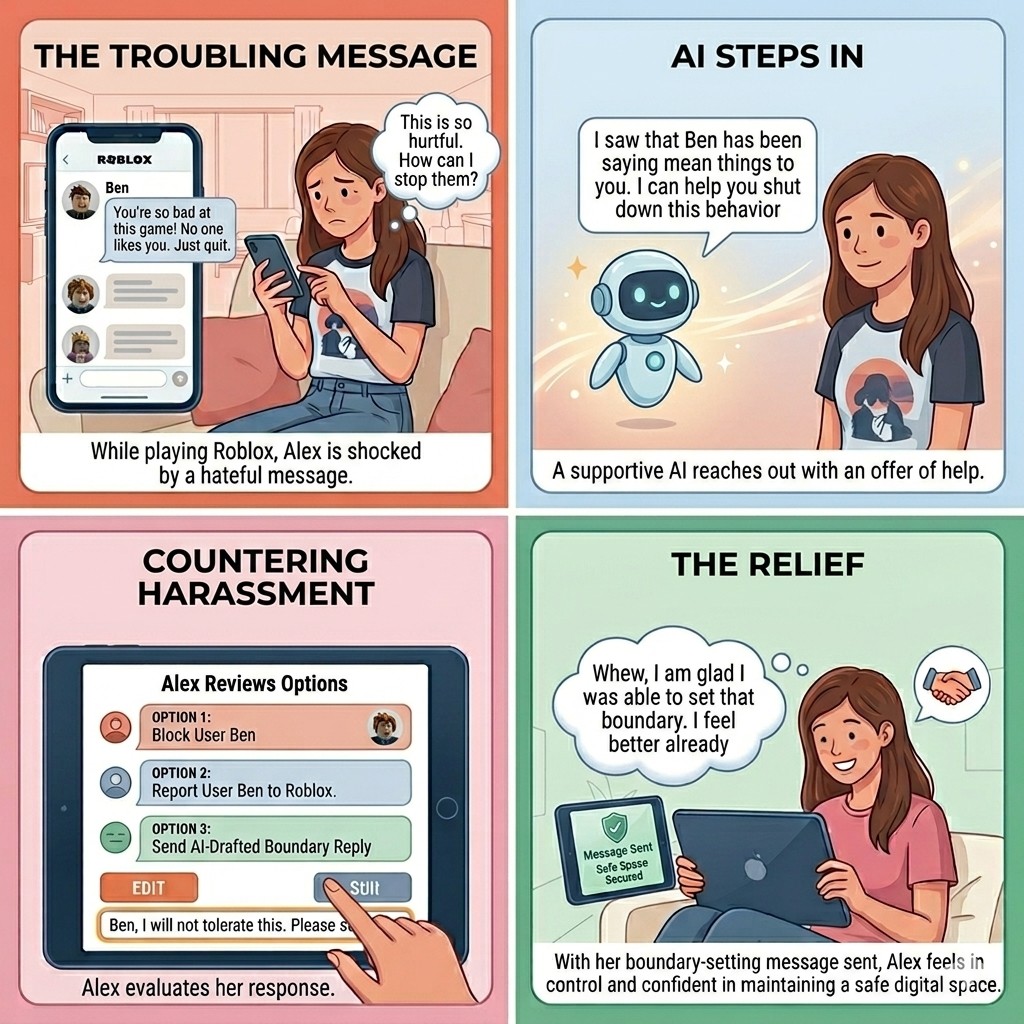
Storyboard
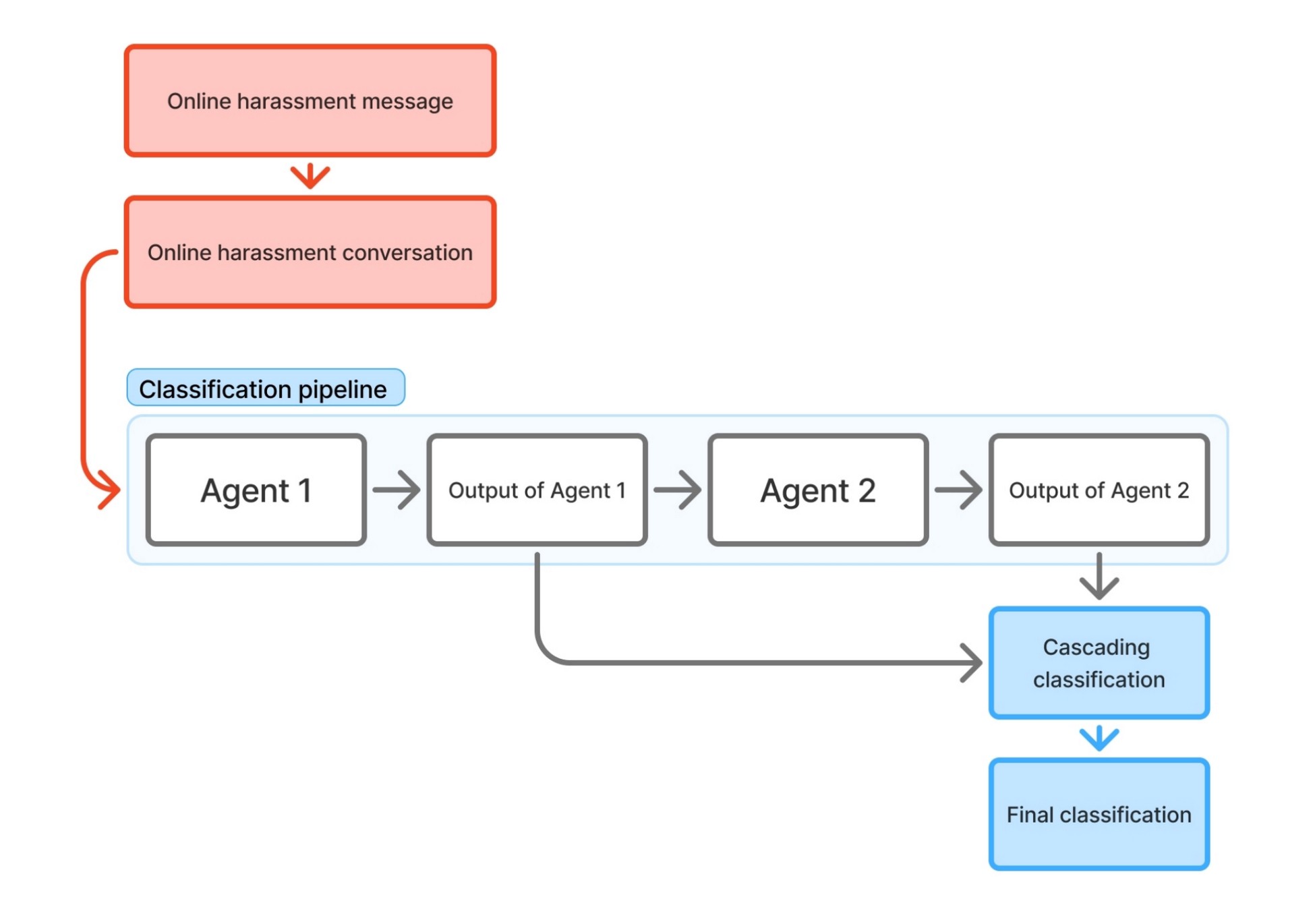
Classification pipeline
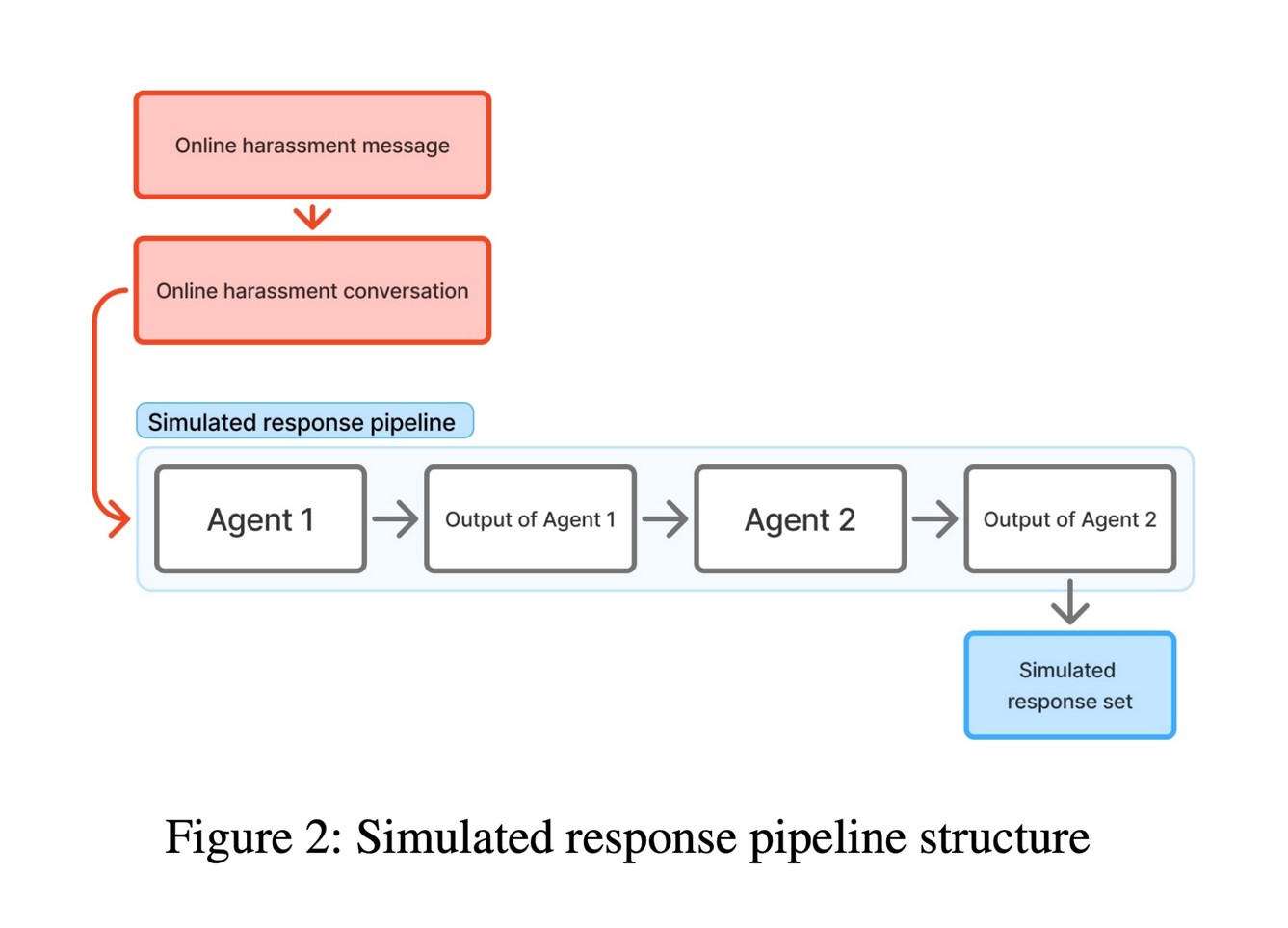
Simulated response pipeline
Problem space
Private-message harassment is under-studied, and existing tools put the work on the user.
When a user receives a hostile message in their DMs, the platform's response options are limited: report or block. This places the burden of stopping harassment on users already managing its emotional toll.
Two research gaps shaped the questions I explored
- 01
AI detection of online harassment for adolescents is understudied.
- 02
Most harassment research focuses on public posts, while private messaging is ignored due to scarce data.
The team addressed both gaps through a dataset of Instagram DMs voluntarily donated by adolescent users via IRB-approved grants.
RQ1
How can we effectively identify online harassment in private messaging at scale?
RQ2
How can we help people more appropriately address online harassment in private messaging?
Task
Designing and running a study with a 3-person team.
As UX Researcher on a 3-person team, I helped design and run a study testing whether LLMs could support users in two ways: recognizing harassment as it happens, and suggesting responses that work.
My responsibilities
- Literature review and research-gap identification
- Study design (LLM pipeline architecture, human-labeling protocol, response-evaluation rubric)
- Codebook development and inter-rater reliability testing
- Gathering structured feedback from labelers
- Comparative analysis (LLM responses vs. what users actually receive)
- Manuscript co-authorship
Constraints
- Strict ethical protocols throughout
- Acknowledging that different things are 'helpful' for different people
- Limited context beyond message content (a privacy trade-off)
Action 1
Two pipelines, one dataset, and a labeling protocol for structured user feedback.
Dataset
A subset of an Instagram DM corpus donated by adolescents through joint grants. After cleaning:
- 80,056 messages
- 26 adolescent data donors (ages 12 to 18)
- Multi-message conversations preserved with prior messages as context
Phase 1 — Detection (RQ1)
I designed a labeling protocol that gave the LLM pipeline feedback to learn from. Labelers worked from a shared codebook. Each message was labeled by one person, then re-labeled by a second person who couldn't see the first label, and a third labeler resolved any disagreements. Those disagreements told us which cases were genuinely ambiguous, and helped us iterate on the LLM's prompts.
- 14,607 messages labeled
- 7,531 used for evaluation (excluding messages sent by the donor themselves)
- The pipeline read each message together with the prior 50 messages, because harassment in DMs depends on what came before
Phase 2 — Response generation (RQ2)
For each conversation flagged as harassment, the pipeline generated 3 suggested responses, based on 9 strategies sourced from the literature.
The strategies serve two goals:
- Deterrence: warning the harasser, denouncing the message, pointing out hypocrisy
- Promoting wellbeing: showing empathy, demonstrating understanding, repairing the relationship
- Several strategies serve both at once
Comparative user testing
Labelers evaluated 100 conversation pairs. Each pair had two responses: one written by the AI, one the user had actually received. Raters didn't know which was which, and the order was randomized.
- 3 evaluators had prior experience in mental health / harm reduction
- 6-question rubric drawn from coping research: stopping the harassment, de-escalating, improving the user's position in the exchange, emotional helpfulness, sounding natural in conversation, and whether ignoring would have been better
Action 2
Key findings
Finding 1. AI-suggested responses are rated more helpful than what users currently receive.
On four measures (stopping harassment, de-escalating, improving the user's position, emotional support), evaluators preferred AI-generated responses over the original ones recipients had actually received. The result was statistically significant.
Finding 2. The responses don't sound like the user yet.
When asked which sounded more natural in the conversation, evaluators preferred the original human responses (also statistically significant). A response that's helpful but doesn't sound like the user isn't ready to ship.
Finding 3. Detection works when the model has prior conversation.
The LLM pipeline reliably identified harassment in private messages, outperforming a BERT baseline and matching a 30-model ensemble. It only worked when given the prior messages in the conversation.
Action 3
Design implications
- Detect with prior conversation, not single messages. Single-message detection misses the back-and-forth that defines private-message harassment.
- Suggest responses; don't auto-respond. A suggested-response feature keeps the user in control while doing the hard work of finding the right words.
- Let users say what they want from a response. A real product should let users (or trusted adults) choose whether the response should focus on stopping the harassment, helping the user feel better, or both.
- Make the responses sound like the user. Editable templates, light personalization, or fine-tuning on a user's writing style are candidates worth testing.
Evolution
What I learned
- Disagreements between labelers were useful, not a problem. They flagged the same ambiguous cases the LLM also struggled with, and helped us improve the prompts. This ambiguity indicated subjective preferences for support.
- Look at where the system fails, not just overall accuracy. Average performance can hide errors that hurt specific groups or specific types of harassment.
- LLM responses need to be tested in a real-world setting. Harassers might be encouraged if someone gives them attention, even if it's negative. A follow-up study should test what happens after the response is sent.
Results + relevance
Study at a glance
80,056 messages · 7,531 reviewed · 100 response pairs · 10 users gave feedback
Detection: how often did each system catch real harassment?
LLM pipeline
65%
With prior context
ML ensemble
40%
30-model vote
BERT baseline
22%
Pretrained toxic-bert
Recall on harassment class. LLM pipeline matched the ensemble on F1 (0.23) and beat the baseline (F1 0.10).
Response: which did users prefer?
Helpfulness · Q1–4 combined
AI 54% / Human 46%
Statistically significant
Naturalness · Q5
AI 29% / Human 71%
Highly significant
At a glance
- Dataset: 80,056 Instagram messages from 26 adolescent donors
- Labeled dataset: 7,531 messages reviewed through a two-round labeling process with a tie-breaker
- Detection: LLM pipeline outperformed BERT baseline, matched a 30-model ensemble
- Response quality: AI-suggested responses rated more helpful than original responses (significant); original responses rated more natural (significant)
- Output: Peer-reviewed preprint; submitted to ICWSM
Publication
Lu, P., Ishfaq, N., Win, E., Rose, M., Strickland, S. R., Biernesser, C. L., Zelazny, J., & De Choudhury, M. (2025). Effectively Detecting and Responding to Online Harassment with Large Language Models. arXiv:2512.14700. https://arxiv.org/abs/2512.14700
Tools + skills
Toolkit
Tools: Overleaf · Excel · Figma · Google Docs · Zoom
Skills: Prompt and rubric design · Mixed-methods research · Human-in-the-loop annotation · Literature reviews